






1. 서론
최근의 행성 자료들은 지상 관측보다는 여러 탐사선들의 다양한 탑재체들에 의해 많은 양의 자료가 여러가지 형태로 공개되고 있다. 천체에 근접하여 관측이 가능한 탐사선 자료는 특히 영상자료에서 두각을 드러낸다. 본 연구에서 활용한 달 영상의 경우에는 해상도 50 cm의 영상을 획득하였으며, 아폴로 착륙선의 형태를 인지할 수 있는 정도이다. 이런 양질의 행성 자료들은 연구의 방법을 다양하게 하고, 연구 내용 또한 풍부하게 만들어주고 있다.
태양계 천체에서 크레이터의 개수는 천체 표면의 상대적인 나이 계산에 이용되는 매우 유용한 나이 계산 연구 방법이다[1]. 특정 영역에 시간이 지남에 따라 일정 비율로 충돌 크레이터가 누적된다는 가정을 전제로 하여 상대적인 나이 계산을 수행하고 있다. Fig. 1에서 보여지는 것처럼 주어진 영역에 대해 다양한 크기의 충돌 크레이터가 몇 개나 있는지를 파악하면 축적된 시간을 알 수 있고, 표면의 생성 시점을 알 수가 있다. 이렇게 계산된 상대적인 나이는 아폴로 탐사선이 가져온 달의 샘플 토양의 방사선 연대 측정을 통해 검증되어질 수 있다.

충돌 크레이터를 이용하여 천체 표면의 상대적인 생성 시기를 결정하는 천체는 대표적으로 화성, 수성, 세레스가 있으며, 그 외에도 명왕성처럼 lava flow가 행성표면을 덮은 시기, 달 표면에 바다가 형성된 시기, 엔셀라두스(토성의 위성)와 가니메데(목성의 위성) 등 얼음이 천체의 표면을 덮은 시기 등을 알 수가 있다.
2. 충돌 크레이터 검출
태양계 천체의 충동 크레이터는 영상을 눈으로 보고 직접 세는 방법으로 진행되어 오다가 최근에는 컴퓨터를 이용하여 머신러닝이나 딥러닝을 사용하여 탐지하고 있다. Robbins and Hynek(2012)[3]는 지름 1 km 이상 되는 크레이터를, Robbins는 지름 100 m 이상 되는 크레이터를 Mars Crater Catalog v1 Robbins라는 데이터 베이스로 정리도 하였다[4]. 수동으로 정리한 크레이터 개수는 지질학적인 의미는 보여 할 수 있으나, 수동 작업하는 과정에서 사람에 의한 오류가 다수 포함되기 때문에 특정 천체의 크레이터 개수의 정의는 내릴 수 없다.
사람에 의한 오차를 최소화하기 위해 자동화를 도입하는데, 크레이터 자동검출방법과 딥러닝을 이용하는 방법이 있다. Stepinski et al.(2012)[5]은 화성의 크레이터를 ‘크레이터 자동 검출(crataer detection algorithm, CDA)’이라는 머신러닝을 도입하여 식별하였다(Fig. 2).

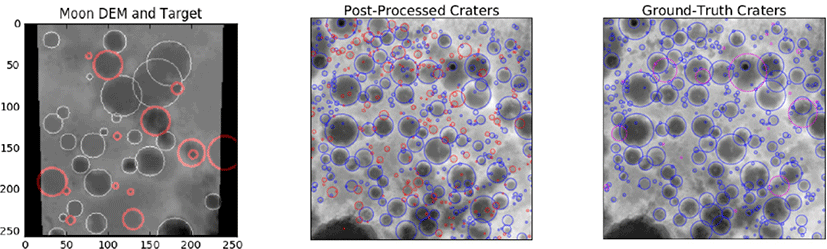
크레이터에 대한 정의는 달의 DEM(digital elevation model)을 이용하는 방법과 panch-romatic 영상에서 크레이터를 정의하는 방법을 사용하였다. 머신 러닝에서 발전하여 딥러닝을 이용하여 크레이터 탐지를 시도하기도 하였다. Siburt et al.(2019)[6]은 convolutional neural networks(CNNs)를 이용하여 크레이터를 식별하였고, 달의 DEM를 정답지로 입력하여 모델을 학습시켰고, 학습 결과 기존에 알려진 크레이터보다 많은 수의 크레이터를 탐지할 수 있었다(Fig. 3).
우리는 달 크레이터 객체 검출이라는 문제 정의를 하고, 딥러닝을 이용하여 크레이터 객체검출을 시도하였다. Lunar Reconnaissance Orbiter(이하, LRO)에 탑재된 LROC WAC 데이터와 LRO archive에서 제공하는 지름 5–20 km 크기의 크레이터의 shapefile(labeling data)을 입력데이터로 사용하였다. 딥러닝 수행 과정은 1) train data set, validation data set, test data set 생성, 2) Yolov5로 객체 검출 모델 개발, 3) train data set, validation data set으로 모델 학습, 4) test data set으로 모델 테스트 및 성능평가를 수행하였다.
데이터셋은 영상데이터와 라벨링 데이터를 세트로 구성하였다. 영상데이터는 LROC WAC 자료로 643 nm 영상, empirical normalized, 위도 ±60이내, 해상도는 약 470m 영상을 이용하였고(Table 1), 라벨링 데이터는 LROC archive 사이트에서 제공받았다. 우리는 지름 5 – 20 km에 대한 크레이터에 대해서만 딥러닝 모델을 생성하였다. Table 1은 영상 입력자료에 대한 정보이며, Table 2는 labeling data로 사용한 shapefile의 정보이며 shapefile 영상은 Fig. 4와 같다. Table 3은 각 데이터를 다운받을 수 있는 사이트 주소이다.
Adopted from Washington University in St. Louis with permission of Author [7].
Adopted from NASA with public domain [8].

| Data type | Available site |
|---|---|
| Lunar images | LODE: https://ode.rsl.wustl.edu/moon/indexProductSearch.aspx Download Link: http://pds.lroc.asu.edu/data/LRO-L-LROC-5-RDR-V1.0/LROLRC_2001/DATA/MDR/WAC_EMP/ |
| Shapefile (labeling data) | http://wms.lroc.asu.edu/lroc/rdr_product_select |
이렇게 획득한 데이터는 다음과 같은 전처리 과정을 거쳤다; 1) 달 좌표계를 픽셀 좌표계로 변환, 2) .img을 .tif와 .png를 거쳐 8bit 영상으로 변환, 3) 원본 영상, percentile_clip(0.5%) 영상, percentile_clip(1.0%) 영상으로 구현하였다. Percentile_clip이란 영상의 히스토그램을 추출한 후 전체 픽셀값 분포에서 상하위 지정 퍼센트에 해당되는 값들을 의미 없는 데이터로 간주하여 제외하는 기법이다. 예를 들면 전체 픽셀의 0.5% 미만과 99.5% 초과되는 픽셀들은 제외하고, 0.5%에서 99.5%로 clip해주는 과정을 의미한다. 영상에서 극단적으로 낮은 값이나 높은 값을 제외시키고자 함에 있다. 전처리된 영상들로 train set 3,800장, validation set 1,004장, test set 1,048장으로 구성하였고, YOLOv5s와 YOLOv5x를 이용하여 6개의 결과를 도출하였다.
객체검출 모델(object detection model)은 딥러닝 기반의 문제 해결 방법 중에 하나이다. 모델은 패치 이미지와 객체 바운딩 박스로 좌표, 카테고리 정보를 받고, 객체의 바운딩박스 좌표와 카테고리(클랙스) 등을 출력하게 된다. 본 연구에서는 YOLOv5s와 YOLOv5x 모델을 사용하였다.
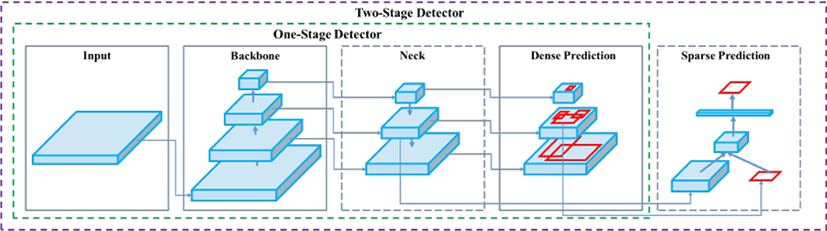
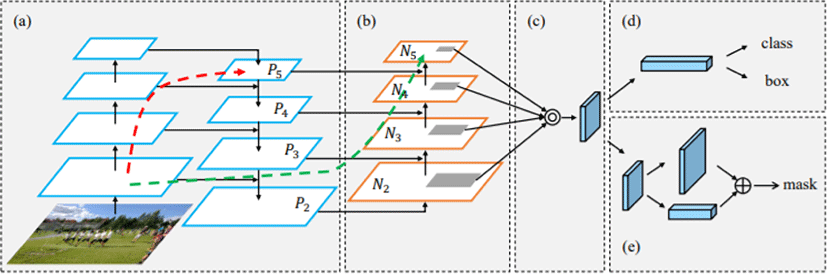
YOLOv5 모델은 single-stage detector인 YOLOv3를 향상시킨 모델로서, v3과 v4 모델의 장점을 살려서 성능을 향상시킨 모델이다. 기존 object detection model들에 비하여 상대적으로 작은 네트워크를 이용해서 학습 속도가 빠르며, YOLOv5의 구조는 일반적인 객체탐지 구성과 큰 차이는 없다[9]. Fig. 5의 구조와 같이 YOLOv5는 backbone, neck, head 부분으로 나눌 수 있으며, backbone은 영상으로부터 feature map을 추출하는 역할이며, CSP-Darknet을 사용하는 부분으로 YOLOv4와 유사하다. Neck은 backbone과 head를 연결해주는 역할이며, head는 추출된 feature map을 바탕으로 물체의 위치를 찾는 부분이다.
YOLO5의 핵심 기술 중 하나는 DenseNet 기반의 CSP(Cross Stage Partial Networks)를 사용하는데 Fig. 6과 같은 구조를 가지고 있다.
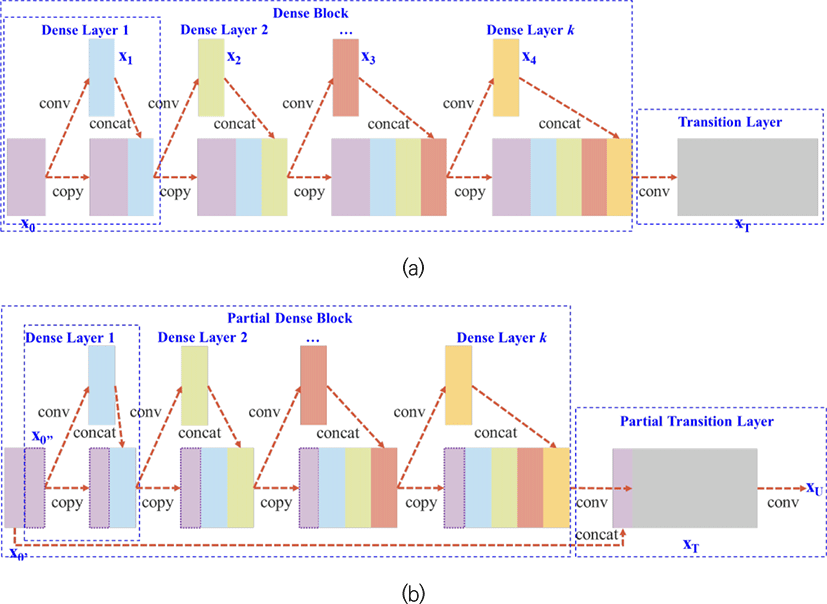
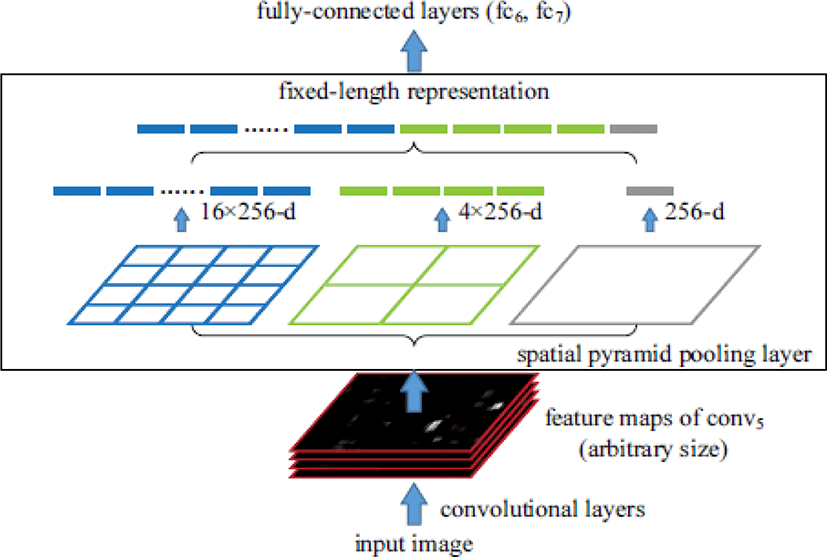
DenseNet은 layer가 깊어짐에 따라 발생하는 증감율 소멸 문제(gradient vanishing)를 해결하기 위해 고안되었는데, DenseNet의 최적화 과정 중 중복되는 증감율(gradient)을 줄여 연산량을 줄이고, 성능을 향상시키기 위해 CSP를 사용했다. 이러한 구조는 DenseNet의 출력값 연결을 통한 재사용을 유지하면서도 중복되는 기울기 정보(gradient information)가 많아지는 것을 방지해준다. 그 뒤 SPPNet(Spatial Pyramid Pooling Network)에 연결되어 neck 부분으로 연결되는데, SPPNet은 기존 CNN 구조들이 fully connected layer의 고정된 이미지 크기를 입력으로 받으며 발생하는 문제점들을 해결하기 위하여 고안되었다. 기존 CNN은 고정된 이미지 크기로 crop/warp 과정을 거치고, 각각의 모든 이미지들을 conv layers에 통과시킨 뒤 fully connected layer에 연결하는 방식이었다면, 이 SPPNet에서는 먼저 전체 이미지를 conv layer에 통과시킨 뒤 SPPNet을 거쳐 fully connected layer에 연결하는 방식이다[11]. Fig. 7에 일련의 과정들이 나와 있다.

SPPNet는 local spatial bins를 polling하여 spatial 정보를 유지한다. Fig. 8과 같이 SPPNet은 YOLOv5에서는 spatial bins를 5 × 5, 9 × 9, 13 × 13 Feature Map을 사용했으며, 최종적으로 5 + 9 + 13 = 27의 크기로 고정된 1차원 배열을 생성하여 Fully Connected Layer의 입력으로 사용했다.
Neck은 backbone과 head부분을 이어주는 부분이다. 전체적으로는 PANet(Path Aggrega-tion Network)로 이루어져 있다. PANet은 FPN(feature pyramid network)에서 발전되었는데, FPN은 단계별로 신경망들을 통과하며 Feature Map을 구성 후 상위 레이어부터 내려오며, Feature를 합친 뒤 객체 탐지를 진행한다(Fig. 9)[12].
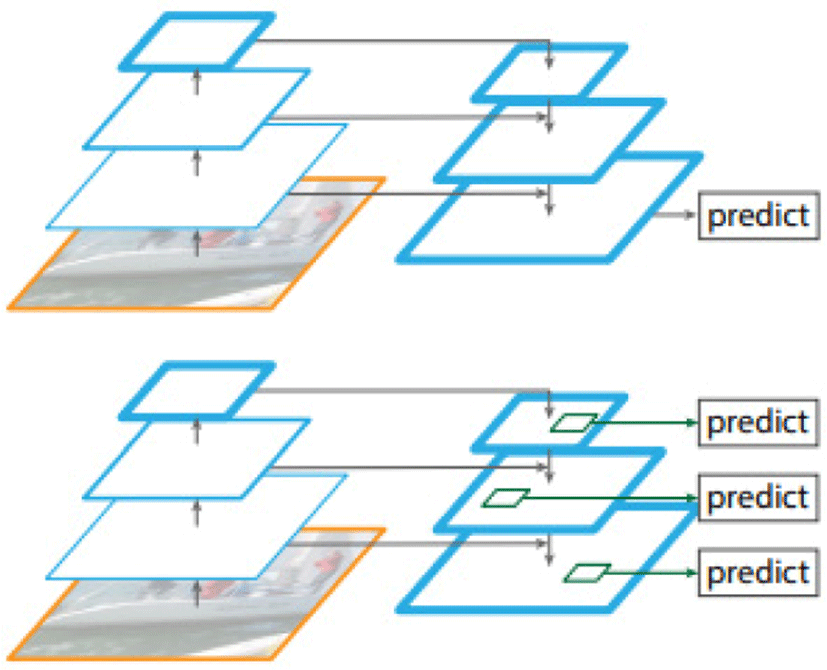
PANet 모델은 FPN에 모델을 덧붙여 만든 것으로서, 일반적으로 먼저 추출된 low-level feature일수록 마지막 단계까지 진행되었을 때(output까지 propagate되면) 먼거리로 인해(먼거리임에) 충분히 반영되지 않는 결과가 도출된다. 이를 방지하기 위해 low-level feature도 결과에 잘 반영되는 방안을 도입한 것이다(Fig. 10).
Head 부분은 추출된 feature map을 바탕으로 물체를 탐지하는 부분으로, Anchor Box를 처음에 설정하고, 이를 이용하여 최종적인 bounding box를 생성한다.
Yolov5는 S, M, L, X의 4종류가 있으며, 구조는 모두 같지만 depth_multiple, width_ multiple 2가지 변수의 차이로 구별을 한다. S가 두 가지 변수가 다 작고 X로 갈수록 커지는데, depth_multiple이 클수록 BottleneckCSP layer가 더 많이 반복되어 더 많은 layer로서 깊어지며, width_multiple이 클수록 모듈의 채널 수가 많아진다. 본 연구에서는 S모듈과 X모듈을 사용하여 결과값을 출력, 비교하였다.
학습시킨 내용을 정리하면 Table 4, 5와 같다. YOLOv5s, YOLOv5x를 backbone으로 하여 크레이터 객체 탐지를 수행하였다. 패치크기는 1,024 × 1,024, epoch는 300회로 모델을 구현하였다. 성능 평가를 위해 iou_threshold 0.6, conf_threshold 0.3을 기준으로 precision, recall, mAP를 계산하였다.
3가지 전처리 과정을 거쳐 만들어진 기본 영상, percentile_clip(0.5%) 영상, percentile_ clip(1.0%) 영상에 YOLOv5s와 YOLOv5x를 적용한 크레이터 탐지 결과는 Fig. 11, 12에서 보여준다.


3. 토의
딥러닝을 이용하여 크레이터를 식별하는 방법에는 해결해야 할 몇 가지 문제점들이 남아 있다. 지금까지의 연구들은 연구자들마다 나름의 크레이터의 정의를 각자 세우고, 거기서부터 크레이터 식별이라는 문제를 풀었다. 이 연구도 마찬가지로 영상에서 크레이터의 정의 및 큰 크레이터들의 경계를 어떻게 둘 것인지에 대한 문제가 향후 과제로 남아 있다.
크레이터는 생성된 이후부터 시간이 갈수록 gardening 효과를 거치면서 그 형태가 뚜렷하지 않다. 딥러닝 라벨링 과정에서 이런 크레이터를 정확하게 라벨링할 수 있는지의 문제와, 이렇게 학습된 모델이 형태가 뚜렷하지 않은 크레이터를 찾아낼 수 있는지가 또 하나의 풀어야 할 과제이다(Fig. 13). 대기가 없는 천체의 표면 gardening 효과는 표면의 나이와도 직결된 문제이기 때문에 크레이터 카운팅을 하는 주 목적인 나이계산을 하기 위해서는 딥러닝을 수행하는 과정에서 정의가 된 후 수행되어야 한다.
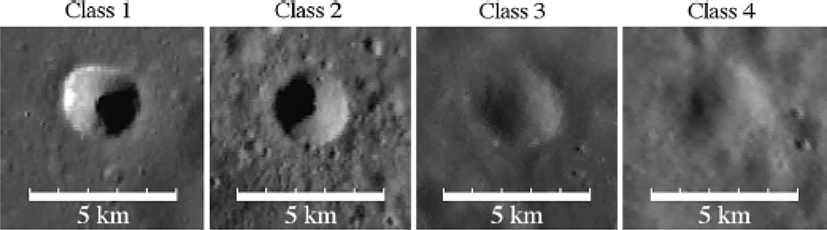
또 다른 문제는 크레이터 크기와 형태이다. Siburt(2019)[6]는 그의 결과에서 약 15픽셀보다 작은 크레이터는 잘 탐지하지만, 큰 크레이터에 대해서는 탐지가 잘 되지 않는다고 하였다. 본 연구에서는 달 표면의 대부분을 차지하는 5 – 20 km를 가진 크레이터에 대해 수행하였다. 달 표면에서는 달 반구를 덮는 lunar basin 및 지름 5 km 미만의 크레이터도 많은 분포를 차지하고 있다. 본 연구에서 수행한 크레이터 지름 5 – 20 km의 모델은 지름 5 – 20 km 이외의 크레이터에 대해서는 탐지가 어려운 것으로 드러났다. 또한 이번 연구에서는 원형 또는 타원형의 독립 크레이터에 대해서만 학습을 하고 테스트를 수행하였다. 하지만 달 표면에는 다양한 크레이터가 분포하고 있고, 이에 대한 정의도 향후 수행되어야 할 과제이다(Fig. 14).

이 연구의 최종 목적은 개발한 모델을 향후 획득하게 될 ShadowCam 영상에 적용하고자 함이다. ShadowCam은 시험용 달궤도선(Korea Pathfinder Lunar Orbiter, KPLO)에 탑재 예정인 NASA에서 개발 중인 달의 영구음영지역에서 물을 탐색하기 위한 목적으로 개발되고 있다. ShadowCam은 영구음영지역의 영상을 secondary scattering된 빛을 이용하여 촬영할 예정이며, 이렇게 획득된 영상은 일반적인 reflectance 영상과 다른 것으로 예상된다(Fig. 15). ShadowCam이 촬영한 기존 영상과는 다른 영상에 본 연구에서 개발한 딥러닝 모델을 적용하여 영구음영지역의 영상에서 크레이터를 식별하고자 한다. 획득되는 영상에서 크레이터 식별을 딥러닝을 통해 시도하는 것은 크기가 작거나 경계가 불분명하거나 또는 또 다른 이유로 인하여 육안으로 판단하기 어려운 영상에서 크레이터를 식별하는 하나의 방법이 될 것이다.

향후, 이 연구는 ShdowCam에 의해 획득될 영상에 적용하여 그 결과를 지켜보고자 한다. 앞서 우리는 LROC/LRO 영상 외에도 MI/Selene data, HIRES data/Clementine 그리고 LOLA의 DEM 자료를 이용하여 모델 학습을 수행하고 결과를 분석할 예정이다. 또한 달 환경과 유사한 수성과 세레스에도 적용하여 딥러닝 기법이 태양계 천체 연구에 도움을 줄 수 있는 방법임을 알리고자 한다.



